Глубокое машинное обучение использует «язык белков», чтобы предсказать их свойства
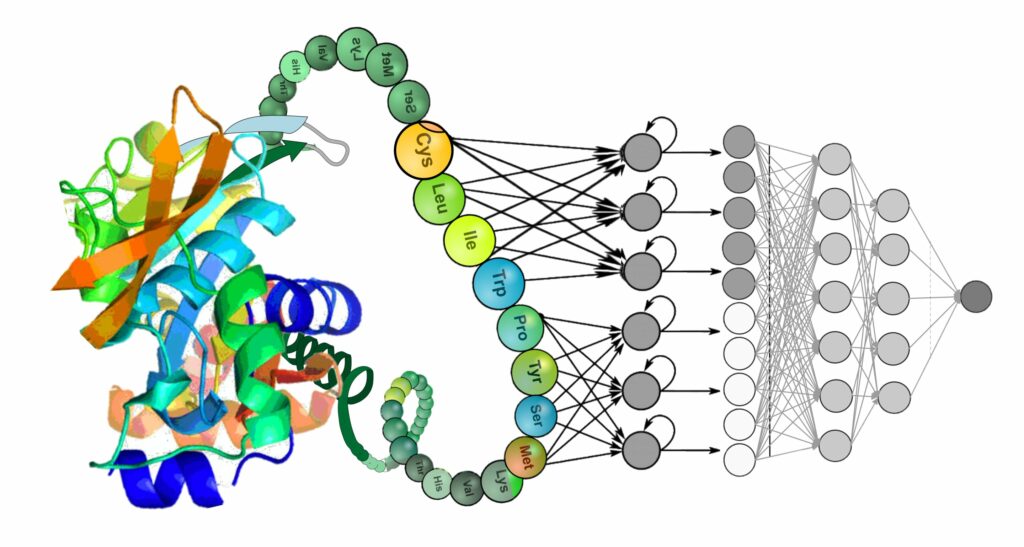
Модели глубокого обучения (deep learning) хорошо зарекомендовали себя при работе с текстами и речью. Однако они также эффективны для решения задач молекулярной биологии и биомедицины, в том числе предсказания функциональных свойств белков на основе их аминокислотной последовательности.
На протяжении многих лет биоинформатики, генетики, нейрофизиологи и другие специалисты в области наук о живом продолжают выяснять биологические функции генов и их продуктов — белков. Для этого им приходится использовать большие и порой имеющие сложную структуру данные, с которыми просто невозможно справиться без помощи машинного обучения и анализа данных.
Напомним, белки — это крупные биологические молекулы со сложной структурой. Они представляют собой длинные цепочки (полимеры), состоящие из множества связанных звеньев-аминокислот (мономеров). Белки могут выполнять самые различные и очень специфичные функции — от формирования «клеточного скелета» до катализа химических реакций, работы в качестве «молекулярных машин» и регуляции различных биологических процессов. Это возможно благодаря их особой трехмерной структуре, которая, в свою очередь, определяется именно аминокислотной последовательностью белка.
В то же время установить связь между аминокислотной последовательностью, структурой белка и его функциями — непростая и пока далеко не решенная задача. Поэтому исследователи из трех различных университетов Турции опубликовали в журнале Nature Machine Intelligence работу, в которой оценили возможность задействовать модели глубокого обучения (deep learning), исходно предназначенные для лингвистического анализа.
Глубокое обучение — разновидность машинного обучения на основе нейронных сетей. Оно называется глубоким, поскольку структура его сетей состоит из нескольких входных, выходных и расположенных между ними скрытых слоев нейронов. Авторы новой публикации рассмотрели как сильные стороны этого подхода, так и его недостатки.
«Полученные с помощью молекулярной биологии данные можно представить в виде языка (по сути, языка генов/белков) таким образом, что последовательность гена или белка окажется чем-то вроде имеющего определенный смысл предложения на естественном языке», — рассказал один из авторов, Тунча Доган (Tunca Dogan). Он считает, что значение такого «языка белков» сводится к особым биологическим, физическим и химическим свойствам этих биомолекул.
«В соответствии с этим работа ставила своей целью построение моделей машинного обучения, которые используют заимствованное у языковых моделей векторное представление в многомерном пространстве (high dimensional numerical embeddings. — Прим. ред.) для белков в качестве данных на входе и которые точно предсказывают их функциональные свойства».
Чтобы успешно оценить модели «белкового языка» и их показатели качества, исследователям пришлось для начала подготовить большие наборы надежных данных. Каждый из таких наборов имеет определенный «уровень сложности».
С помощью этого метода турецкие ученые смогли оценить пригодность разных архитектур «языкового моделирования» (включая BERT, T5, XLNet и ELMO) для выявления в последовательности белков скрытых паттернов. Исследователи считают, что эти незаметные на первый взгляд свойства последовательностей дают ценную информацию о функциональных признаках белков.
«Вероятно, самым примечательным результатом стало то, что эти модели глубокого обучения смогли успешно установить функциональные свойства белков, руководствуясь исключительно последовательностью аминокислот, хотя это довольно трудная задача. К тому же это хорошо согласуется с результатами других недавних исследований по предсказанию структуры (например, AlphaFold2 от Deepmind и RoseTTAFold от лаборатории Бейкера), в которых в качестве исходных данных использовали именно последовательность», — добавил Доган.
Новый подход и подобные ему методики могут иметь множество практических приложений, включая разработку персонализированных методов лечения.